VIHand: Enhancing 3D Hand Pose Estimation with Visual-Inertial Benchmark
|
|
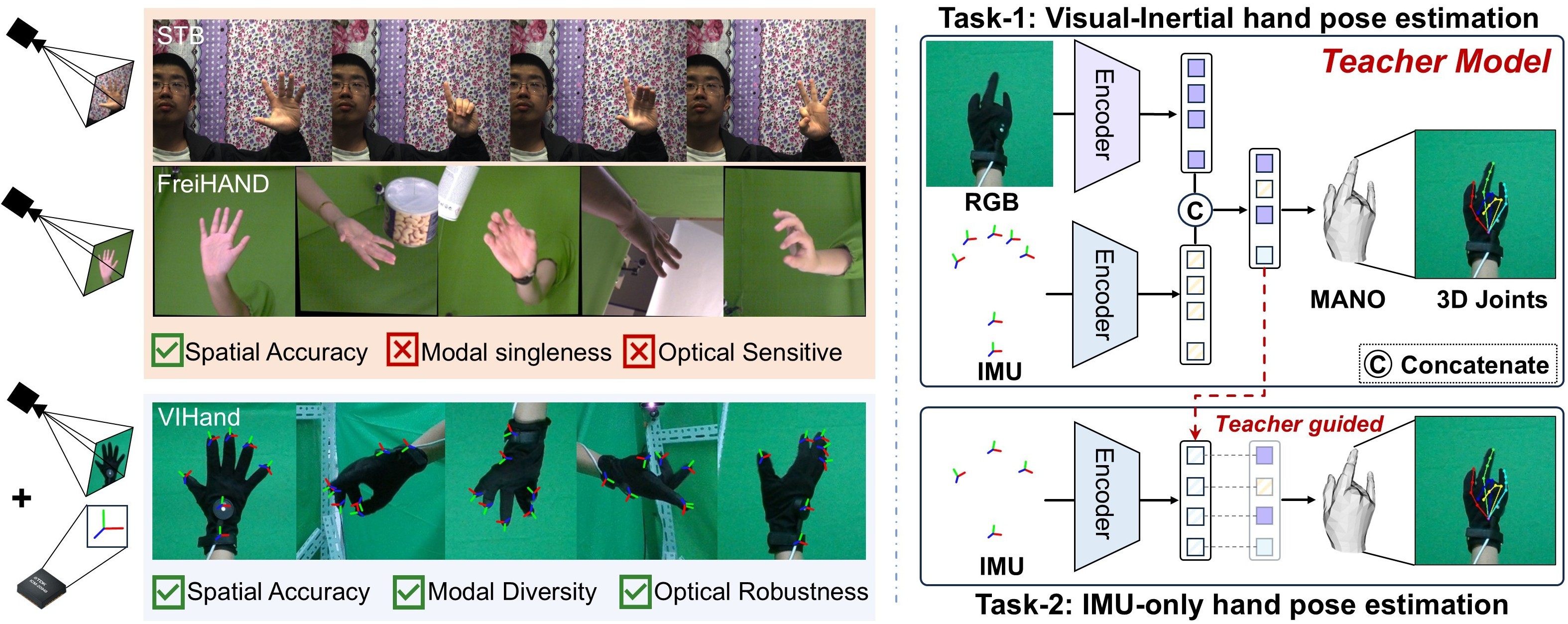
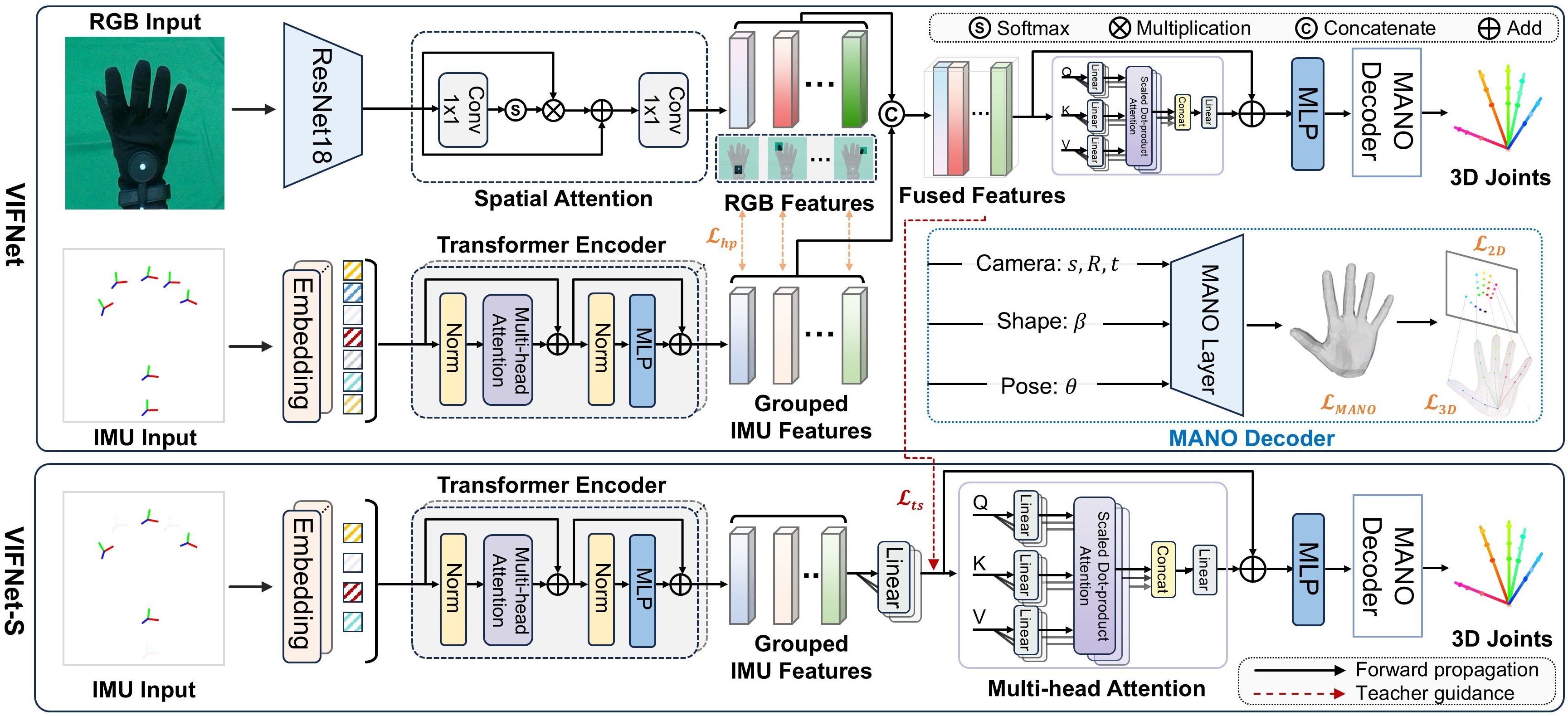
VIHand is the first large-scale glove-worn dataset for visual-inertial hand pose estimation, containing over 1.4 million synchronized RGB-D and IMU frames from 15 subjects. It provides accurate frame-level 3D joint annotations across complex gestures, enabling comprehensive research in HPE tasks, including multimodal fusion, cross-modal knowledge transfer and cross-modal data generation, etc.